Transforming Data Enrichment with the Power of GenAI
Introduction : Rethinking Data Enrichment in a GenAI Era
Data enrichment isn't just about filling in blanks in a dataset. It’s about transforming raw, fragmented data into something truly useful—information that can drive smarter decisions, sharper marketing campaigns, and better business outcomes.
Recently, while working with a SaaS client in the healthcare industry, I encountered a challenge that made me rethink how we handle data quality altogether. My client was preparing for a critical marketing campaign and needed a clean, enriched database of leads for precise targeting. The problem? The data was incomplete, inconsistent, and spread across 120,000+ entries.
We needed a solution to classify two critical data points for each lead:
Was the lead an Individual (like a private practitioner) or an Organization (like a hospital or clinic)?
What was the company's Main Specialty?
Initially, we tried a traditional rule-based approach using Power Query. It worked—to an extent. But as we scaled, its limitations became clear. So, I proposed experimenting with Generative AI to automate and refine the process. This blog shares the journey my client and I took, comparing both methods and highlighting key learnings about prompt engineering and why fine-tuning an AI model can make all the difference when working with data.
The Challenge: Preparing Lead Data for a Marketing Campaign
The project started like many others: a dataset that looked decent at first glance but became more complex the deeper we explored.
The COO and Marketing Director had a clear goal. They needed their leads enriched to target healthcare providers effectively in their next campaign. Yet, as we began consolidating data from multiple sources, gaps emerged. Some entries were labeled with vague terms like "Health Center" or "Dr. Smith," while others were missing specialty information altogether.
After merging the data, we had over 120,000 leads. Manual review was out of the question, so we needed a way to classify both Company Type and Main Specialty at scale while maintaining accuracy and consistency.
I suggested we start with the familiar: a rule-based approach using Power Query.
The First Attempt: Rule-Based Classification Using Power Query
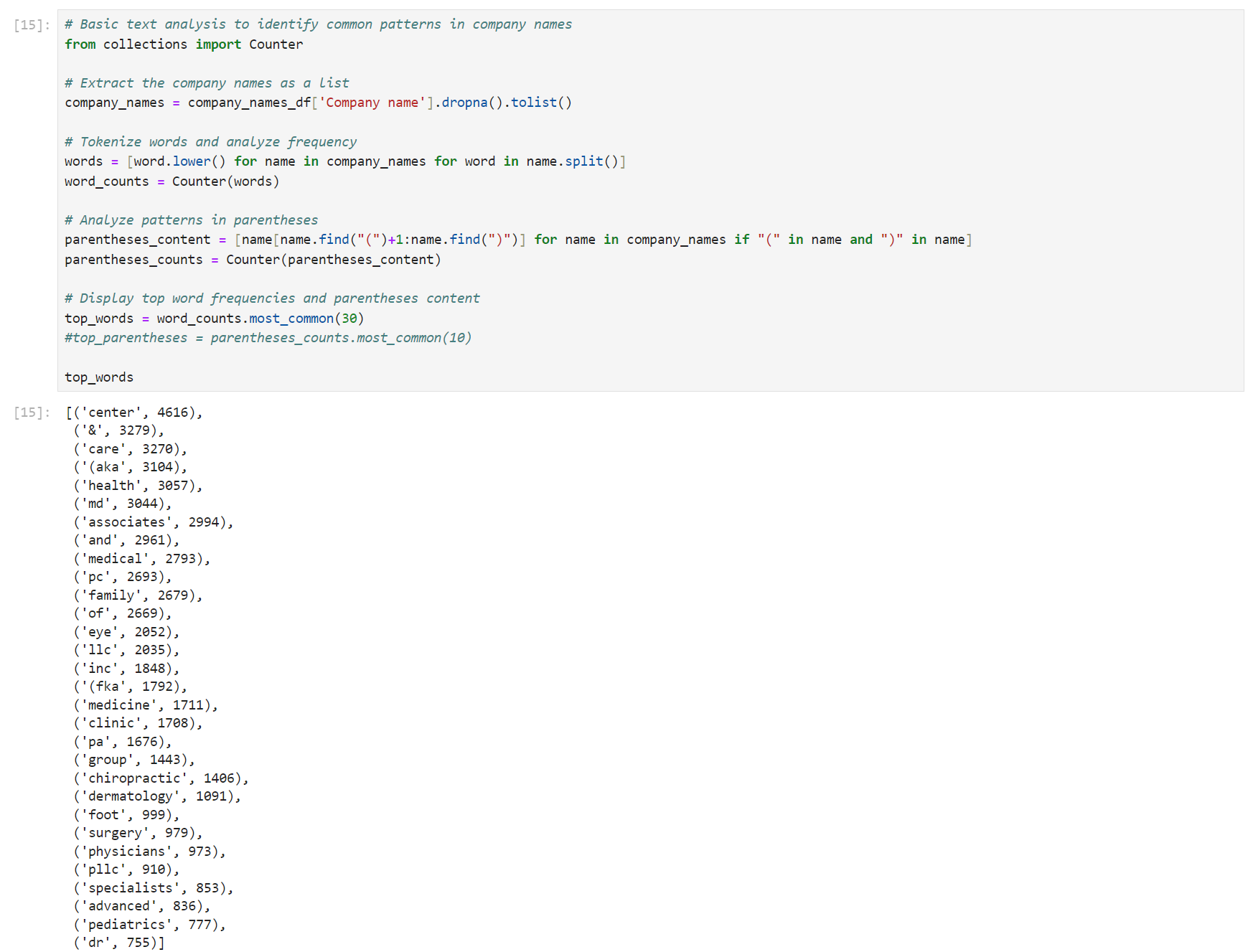


We began with what felt like the most straightforward approach: building dictionaries to classify the data.
To create them, I ran a basic text frequency analysis on the dataset, identifying the most common terms associated with individual practitioners and medical specialties. This analysis helped me create two separate dictionaries:
Individual Identifiers: Terms like
"MD","PhD","Dr.","PA".Medical Specialties: Keywords like
"Cardiology","Dentistry","Pediatrics".
The logic was simple:
If a company name contained words from the Individual dictionary, it was classified as an Individual.
If words from the Specialty dictionary matched, the primary specialty was assigned.
Otherwise, it defaulted to General or required further review.
The results? They were decent—but not without issues.
The approach worked when data was clearly structured, but it struggled with ambiguity. "Dr. John Doe Pediatrics" was easy to classify, but "Premier Health Clinic" returned inconsistent results. The system was brittle. Whenever we discovered new terms, the dictionaries had to be updated manually, and the process felt increasingly cumbersome as the dataset grew.
It was obvious that this rule-based method wasn’t scalable. That’s when I introduced Generative AI into the conversation.
A Smarter Approach: Using GenAI for Data Enrichment

I proposed an experiment: let’s try using GPT-4o, a generative AI model capable of understanding language and context far beyond keyword matching.
The idea was straightforward—feed the company name into the model and let the AI classify both Company Type and Main Specialty based on context. But, as I quickly discovered, how you prompt the model matters—a lot.
At first, I used a simple instruction:
"Classify the following company name as either an Individual or Organization and identify the company's primary specialty."
The results were underwhelming. The AI was inconsistent, sometimes misclassifying data due to vague prompts. I realized I wasn’t giving the model enough direction.
This led me to explore the power of prompt engineering—a critical lesson in this project.
Why Prompt Engineering Matters More Than You Think
Prompt engineering was a game-changer. I learned that the model needs very clear instructions to maintain data consistency—especially when working with structured datasets like this one.
I reworked the prompt entirely. Instead of vague instructions, I built a more precise, structured prompt:
Clear Classification Logic: Explicitly define what qualifies as an Individual or Organization.
Structured Output: Enforce a strict JSON format for uniformity.
Examples for Context: Provide a few sample entries to show the expected output.
This refinement alone drastically improved the model’s consistency. For the first time, it felt like the AI understood the task rather than just matching patterns.
But there was still one area where I saw room for improvement: consistency across thousands of entries. That’s when I explored fine-tuning.
Taking It Further: Fine-Tuning for Better Accuracy and Consistency
While the improved prompt delivered solid results, I realized that fine-tuning could take the process even further.
Fine-tuning allowed us to train a custom model specifically on healthcare data. Instead of relying on general language patterns, the model was exposed to thousands of labeled examples from our dataset.
The results were undeniable:
Consistency: Entries like
"Smith Medical Center"and"Smith MD"were now handled uniformly.Reduced Prompt Complexity: The model required fewer instructions because it had learned the patterns.
Improved Edge Case Handling: Ambiguous terms like
"Health Group"were now classified correctly.
The effort paid off. The model consistently delivered accurate, high-quality outputs with less manual review needed.
Final Thoughts: What This Experience Taught Me
This project reaffirmed something powerful: Generative AI isn’t just a tool—it’s a paradigm shift for data management.
Key takeaways?
Prompt Engineering Matters: The clarity of your instructions directly influences the results.
Fine-Tuning Makes AI Smarter: When the task involves structured data, fine-tuning can elevate both consistency and accuracy.
AI Can Be Trusted—If Used Correctly: With the right setup, AI outperforms manual methods in both speed and quality.
If you’re working with large datasets and want to ensure clean, enriched, actionable data, the combination of GenAI + thoughtful prompt design might be exactly what you need.